As the use of big data continues to expand across various industries, it's important to recognize that the very attributes that define big data—volume, velocity, and variety—also contribute to the growing complexity of data management. But what exactly does big data offer us? The primary advantage lies in its ability to uncover deep, intelligent, and valuable insights from vast amounts of information. This is where machine learning plays a crucial role in transforming raw data into meaningful knowledge.
In a recent study, researchers evaluated the performance of 179 different classification algorithms across 121 datasets. They found that Random Forest and Support Vector Machines (SVM) consistently outperformed other methods, with Random Forest achieving the highest accuracy in over 84% of cases. This highlights the effectiveness of these techniques in handling complex data patterns. The purpose of this article is to explore the question: "How many tools do you need for big data analysis?"
Classification MethodsBig data analysis heavily relies on machine learning and large-scale computing. Machine learning can be broadly categorized into supervised learning, unsupervised learning, and reinforcement learning. Among these, supervised learning includes classification, regression, ranking, and matching tasks. Classification is one of the most common applications, used in areas such as spam detection, facial recognition, user profiling, sentiment analysis, and web categorization. It is also one of the most well-researched and widely applied fields in machine learning.
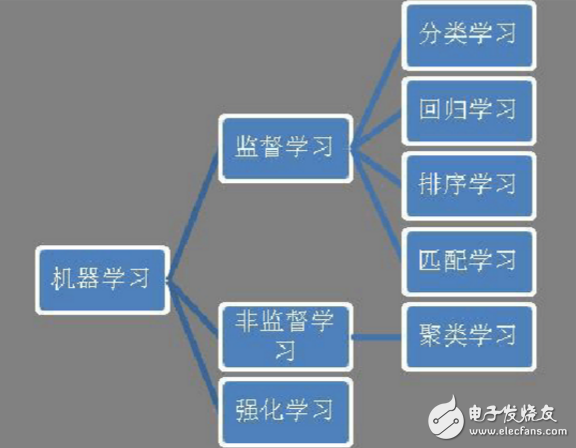
Figure 1: Machine Learning Classification System
Fernández-Delgado et al. conducted an extensive evaluation of 179 classification algorithms on 121 UCI datasets. Their findings showed that Random Forest and SVM were the top performers, with only a small gap between them. In most cases, Random Forest outperformed 90% of the other methods, making it a strong choice for many applications. This research underscores the importance of selecting the right algorithm based on the specific characteristics of the data and the problem at hand.
Some Practical ExperiencesWhen it comes to big data analysis, how many machine learning methods are actually necessary? Let’s look at some long-standing empirical observations in the field. The accuracy of predictions depends on the algorithm, the nature of the problem, and the dataset itself, including its size and features.
Generally, ensemble methods like Random Forest and AdaBoost, along with SVM and Logistic Regression, tend to deliver the best results in classification tasks. However, no single method works perfectly in all situations. Each has its strengths and limitations depending on the context.
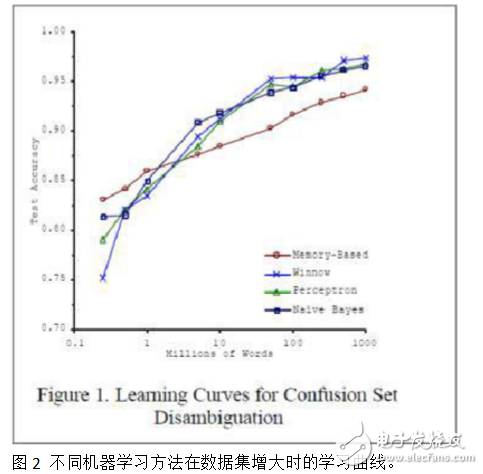
The performance of different algorithms varies significantly when dealing with small datasets, but as data grows, the differences tend to diminish. This means that under big data conditions, more robust methods may not always be necessary. As shown in the experiments by Blaco & Brill (see Figure 2), even simpler models can perform well with sufficient data.
For simpler tasks, Random Forest and SVM are often sufficient, but for complex problems like speech or image recognition, deep learning methods have proven to be more effective. Deep learning focuses on building complex models capable of capturing intricate patterns, which is becoming a major direction in future research.
In real-world applications, feature selection is often more critical than choosing the algorithm itself. High-quality features lead to better classification outcomes, and extracting them requires a deep understanding of the underlying problem.
Test Chamber,Climatic Test Chamber,Humidity Test Chamber,Temperature Humidity Test Chamber
Wuxi Juxingyao Trading Co., Ltd , https://www.juxingyao.com