As the use of big data continues to expand across various industries, it's important to recognize that the very characteristics of big data—such as volume, velocity, and variety—contribute to the growing complexity of modern databases. However, despite this complexity, big data offers significant advantages by enabling us to extract intelligent, in-depth, and valuable insights from vast amounts of information. This ability to uncover hidden patterns and correlations is one of the most powerful aspects of working with big data.
In a recent study, researchers evaluated the performance of 179 different classification algorithms across 121 datasets. The results showed that Random Forest and Support Vector Machines (SVM) consistently achieved the highest accuracy, often outperforming other methods. This article explores the question: "How many tools do you need for big data analysis?"
Classification MethodsBig data analysis largely depends on machine learning and large-scale computing techniques. Machine learning can be categorized into supervised learning, unsupervised learning, and reinforcement learning. Among these, supervised learning includes classification, regression, ranking, and matching tasks (as shown in Figure 1). Classification is one of the most common applications in machine learning, used in areas like spam filtering, face detection, user profiling, sentiment analysis, and web page categorization. It is also the most well-researched and widely applied subfield within machine learning.
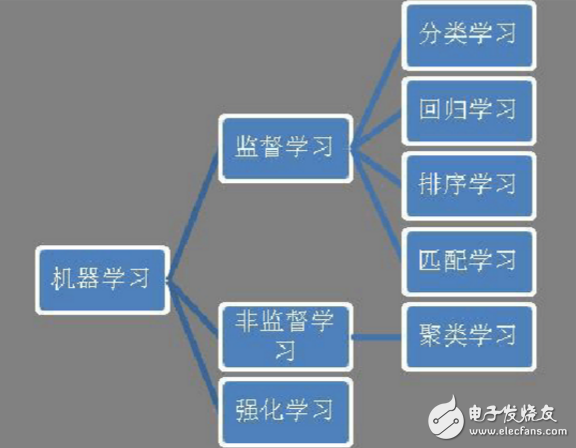
Figure 1: Machine Learning Classification System
Recently, Fernández-Delgado and colleagues published an interesting paper in the Journal of Machine Learning Research. They tested 179 different classification algorithms on 121 UCI datasets, which are publicly available but relatively small in size. Their findings revealed that Random Forest and SVM ranked first and second, with only a small difference between them. In 84.3% of the cases, Random Forest outperformed over 90% of the other methods. This suggests that, in most scenarios, using just Random Forest or SVM can achieve excellent results.
Some Practical ExperiencesSo, how many machine learning methods are actually needed for big data analysis? Let’s look at some empirical rules that have emerged over the years in the field of machine learning.
The accuracy of machine learning predictions depends on several factors, including the algorithm used, the nature of the problem, and the characteristics of the dataset, such as its size and quality.
Generally, ensemble methods like Random Forest and AdaBoost, along with SVM and Logistic Regression, tend to perform best in terms of classification accuracy.
There is no universal “one-size-fits-all†solution. While Random Forest and SVM often deliver top performance, their effectiveness can vary depending on the specific context and data characteristics.
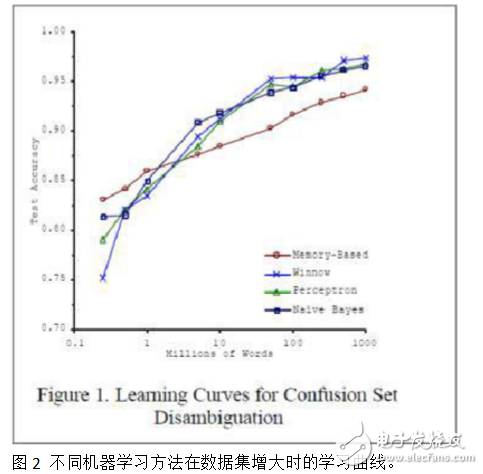
When dealing with smaller datasets, different algorithms may show significant variations in performance. However, as the data size increases, the performance of most algorithms tends to improve, and the differences between them become less pronounced. This trend is illustrated in the experimental results from Blaco & Brill, as shown in Figure 2.
For simpler problems, methods like Random Forest and SVM are usually sufficient. But for more complex tasks, such as speech or image recognition, deep learning approaches have proven to be more effective. Deep learning focuses on building complex models, and it is expected to play a major role in future research and development.
In practice, feature selection plays a crucial role in improving classification accuracy. High-quality features can significantly enhance model performance, and extracting these features requires a deep understanding of the underlying problem.
Sand And Dust Test Chamber,Lock Dust Test Machine,Dustproof Test Box,Seal Dust Test Equipment
Wuxi Juxingyao Trading Co., Ltd , https://www.juxingyao.com